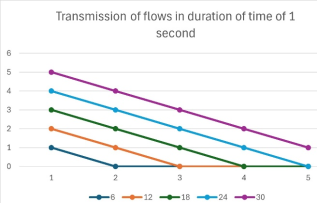
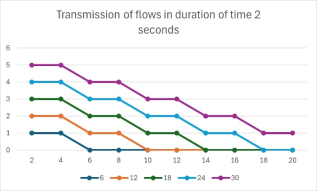
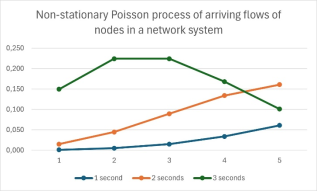
The large amount of information nowadays requires building Data Centers and implementation of optimization models for storing and transferring data. The requirement of limited time of processing the network requests, are needed proper ways of redirection of data and application of algorithms programmatically in different levels. Before this, a data has to be gathered under different circumstances and to be checked if the information has been transferred successfully or not and then based on the results the counts of successful and not successful outcomes to presented and compared with predicate theory. There are many probability models, with which can be analyzed and predicted future events. In this article with the Theory of Index matrices, Graph theory and Theory of probabilities will be analyzed a stochastic process for modeling the times at which flows of a network enter a system. Because the network traffic depends on time, different scenarios of communication durations such as intrinsic time interval and endogenous jump time, will be considered and evaluated if they perform a certain condition. The most proper results of the experiments, which will be calculated with linear and exponential functions and represented with different Index matrices, can be used in machine learning of Data Center Networks.
| Published in | American Journal of Applied Mathematics (Volume 13, Issue 6) |
| DOI | 10.11648/j.ajam.20251306.18 |
| Page(s) | 462-468 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Index Matrices, Network Model, DCN, Fat-Tree Network Model, Probability Theory, Prediction, Poisson Process Model, Broadcast
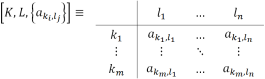 ,
, IM | Index Matrix |
L-IM | Logical IM |
DCN | Data Center Network |
| [1] | Atanassov, K. Index Matrices: Towards an Augmented Matrix Calculus. Springer, Cham (2014). |
| [2] | Todorova, S. Overview of publications on index matrices. (2022-2023) Yearbook of Section "Informatics". Union of Scientists in Bulgaria. pp. 32-62. Tom XII (Volume XII). |
| [3] | Atanassov, K. Bureva V. Short course on discrete structures. Avangard Prima. Sofia. 2018. |
| [4] | Roua Touihri. optimizing routing and resource allocation in sdn-based server only data center networks for private cloud architectures. Hardware Architecture [cs.AR]. Université Paris-Est, 2021. English. NNT: 2021PESC0061. |
| [5] | Todorova, S. Research of the index matrices and their applications. University "Prof. A. Zlatarov" (AU). Faculty of Technical Sciences. Academic degree: Doctor (PhD). 30.09.2024. Supervisor: Assoc. Prof. Veselina Kuncheva Bureva, PhD; Assoc. Prof. Nora Angelova Angelova, PhD. Reviewers: Acad. Prof. Krassimir Todorov Atanassov, DSc DSc Assoc. Prof. Velin Stoqanov Andonov, PhD. Burgas. 113 pages. |
| [6] | Robert G. Gallager. Stochastic Processes: Theory for Applications. Cambridge University Press. Kindle Edition. 2013. |
| [7] | Yu-Dong, C., Li, L., Yi, Z., & Jian-Ming, H. Fluctuations and pseudo long range dependence in network flows: a non-stationary Poisson process model. Chinese Physics B, 18(4), 1373. 2009. |
| [8] | El, Fawal, A. H., Mansour, A., & Nasser, A. Markov-Modulated Poisson Process Modeling for Machine-to-Machine Heterogeneous Traffic. Applied Sciences, 14(18), 8561. 2024. |
| [9] | Todorova, S. Representation with Index Matrices Discrete Random Variables. Am J Appl Math. 13(1): 57-63.2025. |
| [10] | Farhi, S. Nenov, G. Kuyumdzhiev, T. Practical circuits with switched capacitors (SC - circuits). State Publishing House "Technika". Sofia. 1987. |
| [11] | Todorova, S Analysis of Charging and Discharging of Capacitor with Fuzzy Index Matrices. Applied Matrix Theory and Principal Component Analysis in the Digital Era [Working Title]. IntechOpen. 2025. Available at: |
| [12] | Todorova, S. Autoreferat of Research of the index matrices and their applications. University "Prof. A. Zlatarov" (AU). Faculty of Technical Sciences. Academic degree: Doctor (PhD). 30.09.2024. Supervisor: Assoc. Prof. Veselina Kuncheva Bureva, PhD; Assoc. Prof. Nora Angelova Angelova, PhD. Reviewers: Acad. Prof. Krassimir Todorov Atanassov, DSc DSc Assoc. Prof. Velin Stoqanov Andonov, PhD. Burgas. 113 pages. |
| [13] | Todorova, S. Representation with an Index Matrix, Which Elements are Derivative Functions, Values Read by Arduino Uno and Photoresistor. Tenth Conference on Lighting (Lighting). Sozopol. Bulgaria. 2025, pp. 1-5, |
| [14] | Todorova S., Bureva V. Angelova N. Proykov M. Programme Product for Index Matrices. Book of Abstracts of International Symposium on Bioinformatics and Biomedicine 8-10 October 2020, Burgas, Bulgaria. 2020. |
| [15] | S. Todorova. Method of predicate calculus applying a membership classification rule to create an indexed matrix of belonging. Electronic scientific journal Scientific Atlas. 2021. |
APA Style
Todorova, S., Ivanov, I. (2025). Analyses with Index Matrices Mathematical Models of Network Systems. American Journal of Applied Mathematics, 13(6), 462-468. https://doi.org/10.11648/j.ajam.20251306.18
ACS Style
Todorova, S.; Ivanov, I. Analyses with Index Matrices Mathematical Models of Network Systems. Am. J. Appl. Math. 2025, 13(6), 462-468. doi: 10.11648/j.ajam.20251306.18
AMA Style
Todorova S, Ivanov I. Analyses with Index Matrices Mathematical Models of Network Systems. Am J Appl Math. 2025;13(6):462-468. doi: 10.11648/j.ajam.20251306.18
@article{10.11648/j.ajam.20251306.18,
author = {Stela Todorova and Ivan Ivanov},
title = {Analyses with Index Matrices Mathematical Models of Network Systems},
journal = {American Journal of Applied Mathematics},
volume = {13},
number = {6},
pages = {462-468},
doi = {10.11648/j.ajam.20251306.18},
url = {https://doi.org/10.11648/j.ajam.20251306.18},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajam.20251306.18},
abstract = {The large amount of information nowadays requires building Data Centers and implementation of optimization models for storing and transferring data. The requirement of limited time of processing the network requests, are needed proper ways of redirection of data and application of algorithms programmatically in different levels. Before this, a data has to be gathered under different circumstances and to be checked if the information has been transferred successfully or not and then based on the results the counts of successful and not successful outcomes to presented and compared with predicate theory. There are many probability models, with which can be analyzed and predicted future events. In this article with the Theory of Index matrices, Graph theory and Theory of probabilities will be analyzed a stochastic process for modeling the times at which flows of a network enter a system. Because the network traffic depends on time, different scenarios of communication durations such as intrinsic time interval and endogenous jump time, will be considered and evaluated if they perform a certain condition. The most proper results of the experiments, which will be calculated with linear and exponential functions and represented with different Index matrices, can be used in machine learning of Data Center Networks.},
year = {2025}
}
TY - JOUR T1 - Analyses with Index Matrices Mathematical Models of Network Systems AU - Stela Todorova AU - Ivan Ivanov Y1 - 2025/12/26 PY - 2025 N1 - https://doi.org/10.11648/j.ajam.20251306.18 DO - 10.11648/j.ajam.20251306.18 T2 - American Journal of Applied Mathematics JF - American Journal of Applied Mathematics JO - American Journal of Applied Mathematics SP - 462 EP - 468 PB - Science Publishing Group SN - 2330-006X UR - https://doi.org/10.11648/j.ajam.20251306.18 AB - The large amount of information nowadays requires building Data Centers and implementation of optimization models for storing and transferring data. The requirement of limited time of processing the network requests, are needed proper ways of redirection of data and application of algorithms programmatically in different levels. Before this, a data has to be gathered under different circumstances and to be checked if the information has been transferred successfully or not and then based on the results the counts of successful and not successful outcomes to presented and compared with predicate theory. There are many probability models, with which can be analyzed and predicted future events. In this article with the Theory of Index matrices, Graph theory and Theory of probabilities will be analyzed a stochastic process for modeling the times at which flows of a network enter a system. Because the network traffic depends on time, different scenarios of communication durations such as intrinsic time interval and endogenous jump time, will be considered and evaluated if they perform a certain condition. The most proper results of the experiments, which will be calculated with linear and exponential functions and represented with different Index matrices, can be used in machine learning of Data Center Networks. VL - 13 IS - 6 ER -
Department of Mathematics, Informatics and Physics, Burgas State University “Prof. Dr. Assen Zlatarov”, Burgas, Bulgaria
Biography: Stela Todorova is a Doctor of Technical sciences graduated at the University "Prof. Dr. Asen Zlatarov", Department “CST”, Faculty of Technical Sciences with the topic of her dissertation "Research of the index matrices and their applications". She graduated High School of Natural Sciences and Mathematics “Acad. Nikola Obreshkov”, Bachelor's degree in Informatics and Computer Science and Master's degree in Information Security at BFU, Burgas. Her current research interests are in the field of index matrices, intuitionistic fuzzy sets and etc.
Research Fields: Index Matrices, Fuzzy logic

Faculty of Technicks and Technologies, Trakia University, Stara Zagora, Bulgaria
Biography: Ivan Ivanov is a doctoral student at Trakia University – Faculty of Engineering and Technology, Department of Electrical Engineering, Electronics and Automation. His dissertation is on the topic of “Optimization of packets in the control plane of SDN networks using machine learning”. He holds a Master’s degree in Precision Mechanical Engineering and Instrumentation from the Technical University – Gabrovo (2000) and a Master’s degree in Automation and Computer Systems from the Faculty of Technicks and Technologies - Yambol (2016). He has participated in international scientific conferences, and his research interests are focused on analysis and optimization of SDN network protocols and application of machine learning for network traffic management.
Research Fields: analysis and optimization of SDN network protocols, application of machine learning for network traffic management